Onze meest geliefde tool voor het controleren van een site is Screaming Frog. Er is een gratis versie en een betaalde. De betaalde kost € 239 per jaar, maar die is zijn geld meer dan waard. Hieronder bespreken we de betaalde versie. In de training Webtechniek bespreken we deze tool uitgebreid.
Wil je de betaalde versie, koop dan een licentie en kies in Screaming Frog voor License » Enter License.
17.2 Over Screaming Frog
Screaming Frog is een spider. Dus net zo'n stukje software als Google gebruikt voor het indexeren van jouw site. Hij bezoekt alle pagina's, bekijkt de code en geeft bijvoorbeeld ook terug welke server-response-codes worden gebruikt.
Voorbeelden van wat je kunt controleren:
Gebruik van inline stijlen (zie het hoofdstuk over CSS). Je controleert dan op de code style=".
Dode links
Duplicate titels
Responscodes
Grootte van afbeeldingen
Aanwezigheid alt-tekst
Aanwezigheid alt-attribuut
Aanwezigheid tabellen (die je dan met de hand kunt controleren)
Aanwezigheid Google Analytics- of Piwik-trackingcode
Soms krijgen wij vragen over de privacy: Screaming Frog slaat geen gegevens op, alles wordt opgeslagen op je eigen computer. Geen zorgen over de privacy dus.
17.3 Spideractie voorbereiden en starten
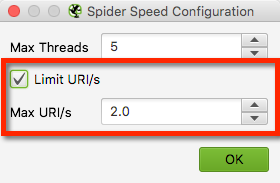
Beperk de snelheid van de spider voordat je start
Het spideren van een site kan belastend zijn voor de website die je spidert en ook voor je eigen computer. Het is daarom vaak verstandig om de snelheid van de spider te beperken. Dat doe je als volgt:
Ga naar Configuration ▸ Speed.
Vink de checkbox Limit URI/s aan.
Kies voor Max URI/s 2,0.
Sla de resultaten op op je harde schijf
Stel in dat Screaming Frog de resultaten van het crawlen opslaat op je harde schijf. Dan werkt de tool efficiënter en kun je geen gegevens kwijtraken als je computer tijdens tussendoor vastloopt.
Ga naar Settings ▸ Storage mode.
Kies Database Storage.
Pas eventueel de map aan waarin de je computer de gecrawlde gegevens moet opslaan.
Pas eventueel andere instellingen aan.
Kies Ok en Restart.
Spideractie starten
Open Screaming Frog.
Ga naar het invoerveld bovenin "Enter URL to spider". Invoerveld voor invoer url in Screaming Frog
Voer daar jouw domeinnaam in en klik op Start.
De spider start nu met het indexeren van de site. Dat kan even duren. Als de spider klaar is, kun je starten met analyseren. onderschrift
Enkele opmerkingen hierbij:
Gebruik geen 'https' of 'http' in de url, want dan kun je gelijk kijken of het redirecten hiernaar goed gaat.
Als de spider na 10 minuten nog doorgaat of als je intussen al duizenden pagina's hebt geïndexeerd, klik dan op stoppen. Op sommige onderdelen, zoals agenda's, blijft ze maar 'doorspideren'.
Als je op een later moment verder wilt met de resultaten kun je deze ook opslaan.
Opmerking: het kan zijn dat de site niet gespiderd kan worden. Dit kan namelijk worden geblokkeerd door de webbouwer of eigenaar.
17.4 Links controleren
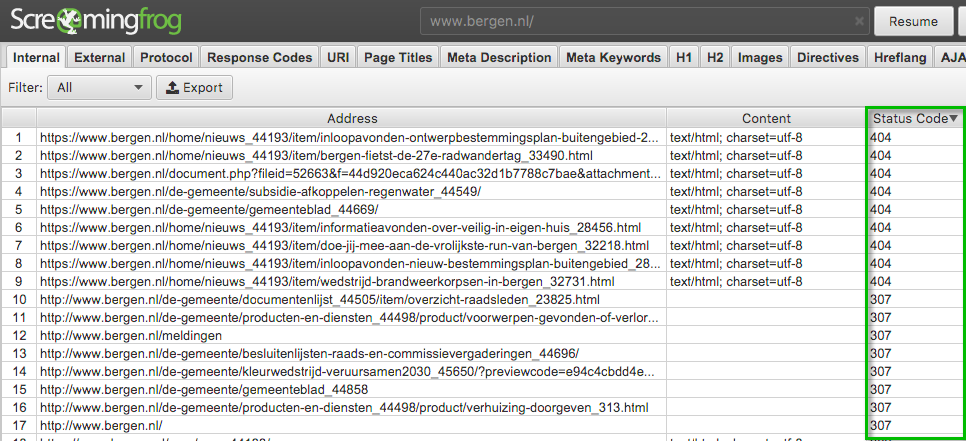
Dode links (404-meldingen) vinden op webpagina's
Zorg dat in het bovenste menu het tabblad "Internal" open is.
Klik in het venster met de webadressen op Status Code, zodat deze aflopend sorteert (vaak 2 x klikken). Als er 404-meldingen zijn, komen deze bovenaan (tenzij er nog 500-meldingen zijn). Statuscodes, aflopend gesorteerd
Selecteer een 404-melding.
Kies uit het ondermenu de optie InLinks. Rechtermuismenu bij 'From' in 'Inlinks'
Daar zie je de pagina staan die leidde tot een 404-melding.
Bekijk daar de anchor text. Dit is de linktekst. Onthoud deze, die heb je zo nodig.
Klik met de rechtermuisknop op de url onder 'From'.
Kies in de pop-up die opent de optie Open From in Browser.
De pagina op de site opent nu. Zoek daar op de ankertekst om de dode link te vinden.
Betekenisloze linkteksten opsporen
'Klik hier, 'dit artikel', en 'lees meer' zijn voorbeelden van betekenisloze linkteksten. Ze vertellen de bezoeker en Google niet wat je krijgt als je die link volgt. Gebruik ze daarom nooit. Maak altijd betekenisvolle linkteksten. Met Screaming Frog kun je controleren of er betekenisloze links op je website staan.
Kies Configuration ▸ Spider ▸ Preferences.
Onderzoek je een Nederlandstalige site? Vervang dan het lijstje Engelse termen bij Non-Descriptive Anchor Text voor dit lijstje met veel voorkomende Nederlandse betekenisloze linkteksten:
klik
hier
klik hier
lees hier
lees meer
meer
meer weten
meer informatie
ga naar
leer meer
start
deze
link
pagina
deze link
deze pagina
dit
artikel
dit artikel
Vul het lijstje eventueel aan met andere betekenisloze linkteksten.
Start de spideractie van je website.
Ga in het bovenmenu naar de tab Links.
Filter de resultaten op Non-Descriptive Anchor Text In Internal Outlinks
Je hebt nu een lijst met pagina's waar betekenisloze linkteksten op voorkomen. Die kun je eventueel exporteren. Maak de betekenisloze linkteksten betekenisvol.
Let op. Je kunt op deze manier alleen betekenisloze interne links opsporen. Misschien staan er op je website ook links naar andere websites met een betekenisloze linktekst. Die achterhaal je hier niet mee. Dat kun je bijvoorbeeld doen via Google.
17.5 Paginatitels controleren
Unieke paginatitels
Het belangrijkste kenmerk van elke pagina is de paginatitel. Deze vind je in het HTML-element title. Voor Google is het belangrijk dat elke pagina een unieke titel heeft. Als dat niet het geval is en je hebt 2 verschillende pagina's met dezelfde titel is dat verwarrend voor Google.
Het is ook belangrijk voor de bezoekers van je site, want als ze in de zoekresultaten 2 resultaten zien met dezelfde titel, welke pagina is dan de juiste?
Vergelijk dit met dat je een boekhandel binnenloopt en er liggen 2 verschillende boeken met dezelfde titel; welk boek was nu het boek dat je wilde kopen?
Ergo: het is een goed streven om elke pagina een unieke titel te geven. Om te controleren of je dat gedaan hebt, gebruik je Screaming Frog.
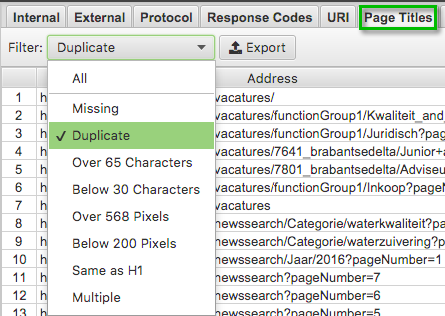
Kies in het bovenmenu voor Page Titles.
Kies in het filter voor Duplicate Duplicate titels in onderdeel Page Titles.
Je krijgt nu een overzicht van pagina's die geen unieke titel hebben, zoals in het voorbeeld hieronder.
Dubbele titels voor Vacatures
Er zijn verschillende oorzaken van duplicate titels, bijvoorbeeld:
Webadressen zijn bereikbaar op http EN https. Het is beter slechts 1 protocol te gebruiken, waarschijnlijk bij voorkeur het https-protocol.
De website is bereikbaar met en zonder www in het webadres. Beter is het om hier 1 domein voor te kiezen.
Alle vacatures hebben de titel 'Vacatures'. Beter is het om hier elke vacature zijn eigen titel te geven, namelijk de titel van de vacature.
1 H1 per pagina
Elke pagina heeft bij voorkeur 1 h1, dus niet 0 of meer dan 1.
Ga naar het tabblad h1 en klik op de kolomkop Occurences.
De kolom wordt oplopend gesorteerd. Als er pagina's zijn zonder h1, dan komen deze bovenaan. Pagina's zonder h1
Klik nog een keer op Occurences, de kolom is nu aflopend gesorteerd. De pagina's met meerdere h1's staan bovenaan. Pagina's met 2 h2's
Open deze pagina (rechtermuisknop) en analyseer de headings met het programma Web Developer (zie vorige hoofdstukken).
Inderdaad zijn er op 1 pagina 2 h1's. Pagina met dubbele h1, zichtbaar gemaakt met Web Developer
Te lange titels
De titel van een webpagina moet betekenisvol en zonder context te begrijpen zijn. Een goede paginatitel is bovendien maximaal 70 tekens inclusief spaties.
Kies in het bovenmenu voor H1.
Kies in het filter voor Over 70 Characters.
Sorteer de resultaten eventueel op H1-1 Lenght en zet de langste titels bovenaan.
Probeer lange titels in te korten tot maximaal 70 tekens inclusief spaties.
17.6 Controleren of pagina's geïndexeerd kunnen worden
De metatag robots gebruik je als je wil dat een zoekmachine iets niet doet op een webpagina. 'Noindex' betekent dat zoekmachines de pagina niet mogen indexeren. Je sluit zoekmachines daarmee uit van die pagina.
Met screaming Frog kun je controleren of dit is toegepast op de juiste pagina's:
Kies in het bovenmenu Pagination.
Sorteer op Indexibility Status.
Controleer of zoekmachines inderdaad uitgesloten moeten worden van de pagina's waar 'noindex' bij staat.
17.7 Controleren of alt-teksten niet te lang zijn
Betekenisvolle afbeeldingen moeten een tekstueel alternatief hebben. Vaak gebruik je daar de alt-tekst voor. Die is liefst niet langer dan 150 tekens inclusief spaties. Met Screaming Frog kun je controleren of dit goed gaat op je site.
Ga naar Images ▸ Alt Text Over 100 Characters.
Kies in het menu voor Bulk export ▸ Images ▸ Images with Alt Text Over X Characters.
Vul eventueel een bestandsnaam in.
Kies eventueel voor een ander bestandsformaat dan .csv.
Kies eventueel een andere locatie voor het bestand.
Kies Save of Save and Open.
Let op: De gewone exportfunctie toont niet de exacte lengte van de alt-teksten.
Gebruik Bulk Export om de exacte lengte te zien van alt-teksten die langer zijn dan 100 tekens
17.8 Grote afbeeldingen opsporen
Afbeeldingen die uit veel bytes bestaan kunnen ervoor zorgen dat een webpagina traag laadt. Dat kan leiden tot een lagere plaats in de zoekresultaten van Google. Met Screaming Frog kun je opzoeken welke afbeeldingen je site trager maken.
Ga naar Images ▸ Over 100 KB.
Sorteer de resultaten op Size en zet de grootste bestanden bovenaan.
Selecteer eventueel met de rechtermuisknop het adres van een grote afbeelding en kies Open in browser. De afbeelding opent nu in een nieuw tabblad van je browser.
Vervang te grote afbeeldingen op je site voor kleinere of regel dat dit geautomatiseerd wordt.
17.9 Zoeken met custom search
Handig in de betaalde versie van Screaming Frog is het onderdeel Custom search. Daarmee kun je zoeken op tekstfragmenten, bijvoorbeeld op het gebruik van inline stijlen (zie het hoofdstuk over CSS).
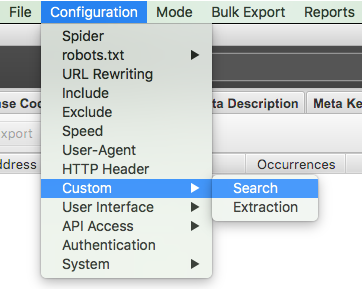
Je komt daar via Configuration ▸ Custom ▸ Search.
Starten custom filters
In het dialoogvenster dat je dan krijgt, stel je de zoekopdrachten in.
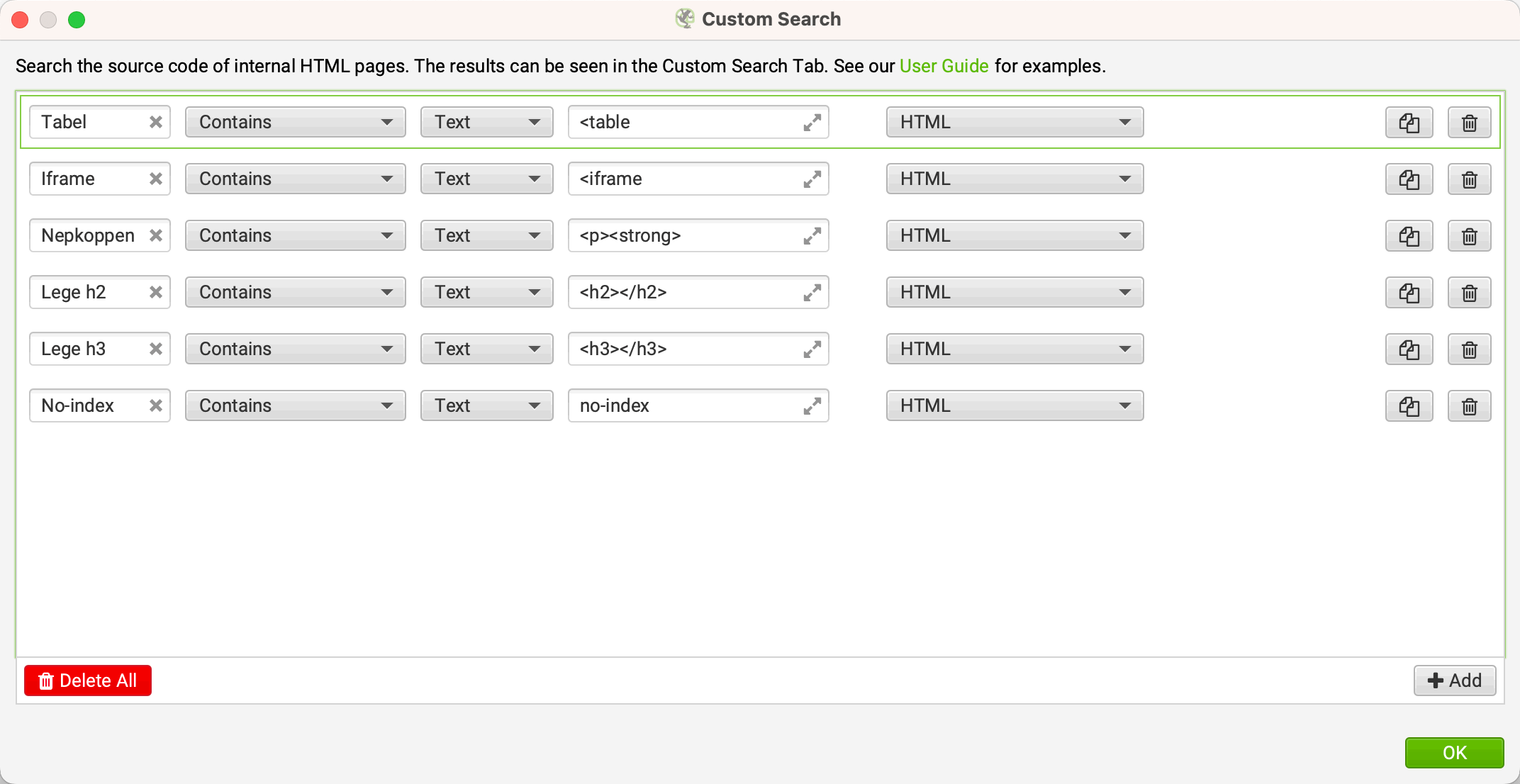
Vul in het 1e veld de naam in van de zoekopdracht. In het 4e veld het tekstfragment. Er zitten bij de andere velden nog meer mogelijkheden. Bekijk ze even, zodat je weet wat er kan.
In het voorbeeld hierboven hebben we bijvoorbeeld een zoekopdracht ingesteld om te kijken op welke pagina's tabellen voorkomen met de hmtl-code "<table".
Indexeer vervolgens de hele site. Ga dan in het bovenmenu naar het item Custom Search en daar zie je alle URL's die voldoen aan een filter.
Je kunt deze optie ook gebruiken om te controleren of de trackingcode van je statistiekpakket overal geïnstalleerd is. Als filter gebruik je dan Does not contain en als het goed is vind je na het spideren geen pagina's waarin de code niet voorkomt.
17.10 Deel van de site onderzoeken of weglaten
Als je slechts een specifiek onderdeel wilt onderzoeken dan kan dat ook. Ook kun je juist iets uitsluiten.
Specifieke directory van de site onderzoeken
Stel we willen alleen het onderdeel trainingen op onze site onderzoeken. Deze staan op www.theinternetacademy.nl/trainingen.
Dan kiezen we voor:
Configuration ▸ Include
Je krijgt een dialoogvenster.
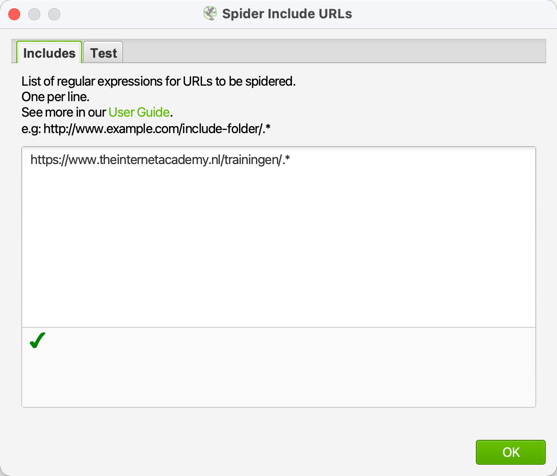
Geef daar het adres van de directory dat je wilt onderzoeken en typ daarachter '.*'. In ons geval is dat: https://www.theinternetacademy.nl/trainingen/.*
Met .* geef je aan: elk teken (een punt) een of meerdere keren (het sterretje). Zo pak je alle bestanden in die directory.
Kies OK.
Start dan de zoekactie op dit onderdeel in Screaming Frog.
Directory uitsluiten
Stel dat we de directory trainingen niet willen meenemen in ons onderzoek.
Configuration ▸ Exclude
Je krijgt opnieuw een dialoogvenster.
Voer in https://www.theinternetacademy.nl/trainingen/.*
Kies OK.
Start dan de zoekactie op de site in Screaming Frog.